
Experimentando con el análisis exploratorio de datos
En este artículo, exploraremos el proceso de análisis exploratorio de datos (EDA) en el contexto de proyectos de aprendizaje automático.
El análisis exploratorio de datos (EDA) es una etapa crucial en cualquier proyecto de aprendizaje automático. En este articulo realizaremos algunos experimentos con EDA para entender mejor cómo podemos utilizarlo para obtener insights valiosos de nuestros datos y mejorar el rendimiento de nuestros modelos.
Artículo anterior: El flujo en proyectos de aprendizaje automático
Un Ejercicio Práctico: Estimando las Ventas de una Cafetería
Para entender el verdadero impacto de un Análisis Exploratorio de Datos (EDA), salgamos de la teoría y vayamos a la práctica con un escenario comercial: Estimar cuántos ingresos generará una cafetería al mes. Este tipo de ejercicios permite que gerentes y dueños de negocio tomen decisiones basadas en datos (Data-Driven) y no en corazonadas.
Puedes seguir este ejercicio interactivo en Google Colab: EDA para Estimar Ventas de una Cafetería
Paso 1: Generación y Carga de Datos
Como primer paso, necesitamos un historial. Simularemos los datos de 365 días operativos de la cafetería, con variables que van desde la temperatura ambiente hasta inversión en publicidad (Ads en redes sociales). Importamos herramientas esenciales del stack clásico de Python: pandas para manejar las tablas, y matplotlib/seaborn para gráficos.
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as plt
import seaborn as sns
# Semilla para que los datos sean reproducibles
np.random.seed(42)
random.seed(42)
# Generación del dataset (365 días operativos)
n = 365
climas = ["Soleado", "Lluvioso", "Nublado"]
data = []
for _ in range(n):
temperatura = round(random.uniform(15.0, 35.0), 1)
inversion_publicidad = round(random.uniform(10.0, 150.0), 2)
eventos_cercanos = random.choice([0, 1])
descuento_aplicado = random.choice([0, 10, 15, 20])
clima = random.choice(climas)
# Lógica de negocio (Correlaciones simuladas):
# La temperatura baja y los eventos suben ventas. El clima lluvioso invita a tomar café.
ventas = (
500 +
(inversion_publicidad * 2.5) -
(temperatura * 8) +
(eventos_cercanos * 250) +
(descuento_aplicado * 5)
)
if clima == "Lluvioso": ventas += 150
elif clima == "Soleado": ventas -= 50
# Añadimos ruido estadístico para hacerlo realista
ventas += np.random.normal(0, 80)
data.append([temperatura, inversion_publicidad, eventos_cercanos, descuento_aplicado, clima, round(ventas, 2)])
columns = ["temperatura_c", "inversion_publicidad", "evento_local", "descuento", "clima", "ventas_diarias"]
df = pd.DataFrame(data, columns=columns)
df.head()
Paso 2: Conociendo la Data (Exploración Inicial)
Con df.info() comprobamos que no haya datos faltantes (nulos) y los tipos de dato, mientras que df.describe() nos resume la media, los máximos y mínimos diarios de ventas y gastos.
# Un vistazo rápido a la salud de nuestra tabla
print(df.info())
# Estadísticas descriptivas (promedios, cuartiles, mín/máx)
print(df.describe())
Dando como resultado lo siguiente:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 365 entries, 0 to 364
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 temperature_c 365 non-null float64
1 ad_investment 365 non-null float64
2 local_event 365 non-null int64
3 discount 365 non-null int64
4 weather 365 non-null object
5 daily_sales 365 non-null float64
dtypes: float64(3), int64(2), object(1)
memory usage: 17.2+ KB
None
temperature_c ad_investment local_event discount daily_sales
count 365.000000 365.000000 365.000000 365.000000 365.000000
mean 24.648767 82.490247 0.561644 11.684932 735.927151
std 5.687482 40.828333 0.496867 7.270059 204.863687
min 15.100000 10.060000 0.000000 0.000000 226.620000
25% 19.800000 48.400000 0.000000 10.000000 576.890000
50% 24.500000 84.780000 1.000000 15.000000 729.730000
75% 29.600000 120.280000 1.000000 20.000000 879.280000
max 35.000000 149.780000 1.000000 20.000000 1337.220000
Exploremos un poco los resultados:
- La temperatura promedio es de 24.65°C, con un rango entre 15.1°C y 35°C.
- La inversión en publicidad varía ampliamente, con un promedio de
$82.49y un máximo de$149.78. - El 56.16% de los días tuvieron un evento local.
- El descuento aplicado varía, con un promedio de 11.68% y un máximo de 20%.
- Las ventas diarias tienen un promedio de
$735.93, con una amplia variabilidad, desde un mínimo de$226.62hasta un máximo de$1337.22.
Además, no hay valores nulos en el dataset, lo que es una buena señal para el análisis posterior. La amplia variabilidad en las ventas diarias sugiere que hay factores significativos que afectan las ventas, lo que hace que el análisis exploratorio de datos sea aún más crucial para entender estas relaciones.
Paso 3: Visualización Estratégica
La mejor forma de entender nuestros datos es a través de la visualización. Vamos a construir tres gráficos clave para nuestro análisis:
- Histograma de Ventas: Nos dice si nuestras ganancias diarias siguen una curva normal (Campana de Gauss) o si están sesgadas.
- Dispersión (Scatter) Publicidad vs. Ventas: Revela si meter más dinero a los Ads realmente sube las ventas o si llega a un tope (rendimiento decreciente).
- Matriz de Correlación: Es el "santo grial" del EDA. Asignará un valor de -1 a 1 a la relación entre todas nuestras variables.
# 1. Distribución de las ventas (¿vendemos más en días "buenos" o "malos" estadísticamente?)
plt.figure(figsize=(8,5))
sns.histplot(df["ventas_diarias"], bins=20, kde=True, color="brown")
plt.title("Distribución de las Ventas Diarias de Café")
plt.xlabel("Ventas en $")
plt.ylabel("Frecuencia (Días)")
plt.show()
# 2. El impacto de los Ads
plt.figure(figsize=(8,5))
sns.scatterplot(x="inversion_publicidad", y="ventas_diarias", hue="clima", data=df)
plt.title("Inversión en Publicidad vs. Ventas (Coloreado por Clima)")
plt.xlabel("Inversión ($)")
plt.ylabel("Ventas ($)")
plt.show()
# 3. El mapa de calor (Heatmap)
plt.figure(figsize=(8,6))
sns.heatmap(df.corr(numeric_only=True), annot=True, cmap="YlOrBr", fmt=".2f")
plt.title("Correlación de Variables")
plt.show()
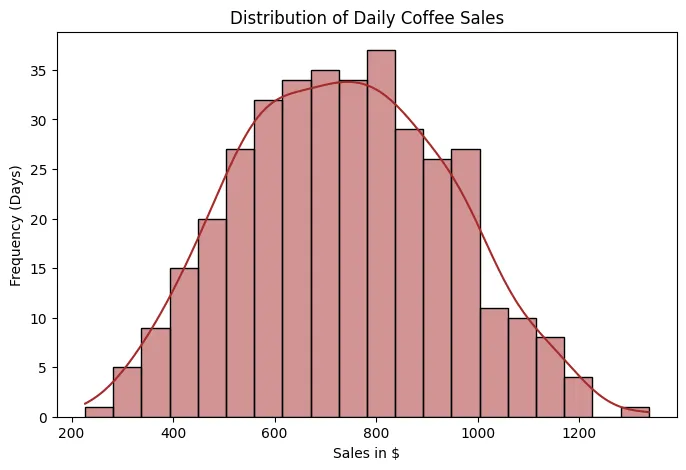 Histograma de Ventas
Histograma de Ventas
Comencemos con el histograma, que nos permite visualizar cómo se distribuyen las ventas diarias a lo largo del tiempo. En este caso, observamos que las ventas siguen una distribución aproximadamente normal, con una media cercana a $800. Esto significa que la mayoría de los días las ventas se concentran alrededor de ese valor promedio, y que los días con ventas muy bajas o muy altas son menos frecuentes y se distribuyen de manera relativamente simétrica a ambos lados.
- ¿Por qué es importante identificar una distribución normal?
Porque muchos modelos estadísticos y de machine learning, como la regresión lineal, el análisis de varianza o ciertos modelos probabilísticos, funcionan mejor cuando los datos (o al menos los errores del modelo) siguen una distribución normal.
Cuando esta condición se cumple:
- Las estimaciones tienden a ser más estables.
- Los intervalos de confianza y pruebas estadísticas son más confiables.
- El modelo no se ve excesivamente afectado por valores extremos.
Si los datos no siguen una distribución normal, puede ser necesario aplicar transformaciones matemáticas (como logaritmo, raíz cuadrada o Box-Cox) para estabilizar la varianza y reducir la asimetría.
- ¿Qué significa "sesgo a la derecha" o "sesgo a la izquierda"?
- Sesgo a la derecha (asimetría positiva): Hay una cola larga hacia valores altos. Esto indica que existen pocos días con ventas extremadamente altas.
- Sesgo a la izquierda (asimetría negativa): Hay una cola larga hacia valores bajos. Esto indica que existen pocos días con ventas inusualmente bajas.
La asimetría es importante porque los modelos sensibles a valores extremos pueden verse distorsionados.
Supongamos que la mayoría de los días las ventas están entre $700 y $900, pero en tres días especiales (por ejemplo, promociones o feriados) las ventas alcanzan $2,500.
Si entrenamos una regresión lineal directamente con esos datos:
- El modelo intentará ajustar una línea que también explique esos picos.
- Esto puede desplazar la pendiente o el intercepto.
- Como resultado, las predicciones para los días “normales” (que son la mayoría) podrían quedar ligeramente infladas.
En cambio, si aplicamos una transformación logarítmica antes de entrenar el modelo:
- Se reduce el impacto de los valores extremadamente altos.
- La distribución se vuelve más simétrica.
- El modelo aprende un patrón más representativo del comportamiento general.
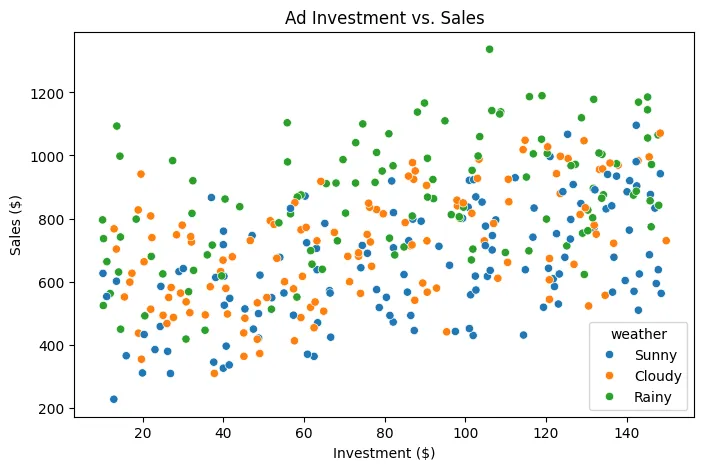 Dispersión entre Inversión en Publicidad y Ventas
Dispersión entre Inversión en Publicidad y Ventas
Los puntos según el clima son de diferentes colores: Azul-Soleado, Naranja-Nublado, Verde-Lluvioso
- Relación principal: inversión vs. ventas
Lo primero que se observa es una tendencia positiva: A medida que aumenta la inversión en publicidad, las ventas tienden a aumentar.
Esto indica una correlación positiva entre ambas variables. No parece una relación completamente aleatoria; los puntos muestran una pendiente ascendente general.
En términos de machine learning, esto sugiere que la inversión publicitaria es una variable predictora relevante para estimar ventas (no la única).
- Variabilidad en las ventas
Aunque la tendencia es positiva, los puntos están bastante dispersos verticalmente.
Por ejemplo:
Con una inversión de $100, las ventas pueden variar entre aproximadamente $400 y $1,100 dependiendo de otros factores.
Esto nos dice algo muy importante:
La inversión no explica el 100% del comportamiento de las ventas.
Existen otras variables influyendo (en este caso, sabemos que el clima es una de ellas).
- Impacto del clima
Aquí es donde el gráfico se vuelve más interesante.
Observando los colores:
- Los puntos verdes (lluvioso) tienden a ubicarse en valores de ventas más altos.
- Los puntos azules (soleado) tienden a concentrarse en valores más bajos para el mismo nivel de inversión.
- Los naranjas (nublado) están en un punto intermedio.
Esto sugiere que el clima actúa como una variable moderadora.
Por ejemplo:
Con una inversión de $120:
- Día soleado → ventas alrededor de
$500–900 - Día lluvioso → ventas alrededor de
$700–1,200
En un modelo de regresión simple que solo use inversión, estas diferencias generarían errores grandes.
- Implicación para modelado
Si entrenamos un modelo usando solo inversión:
El modelo capturará la tendencia general, pero tendrá errores sistemáticos dependiendo del clima.
En cambio, si incluimos el clima como variable categórica (por ejemplo usando one-hot encoding):
El modelo podrá:
- Ajustar diferentes interceptos por clima (por ejemplo, un término extra para días lluviosos).
- Mejorar precisión (ya que nos permite capturar esa variabilidad adicional).
- Reducir varianza del error (porque la varianza, es decir, la dispersión de los puntos alrededor de la línea de regresión, se reduce al explicar más factores).
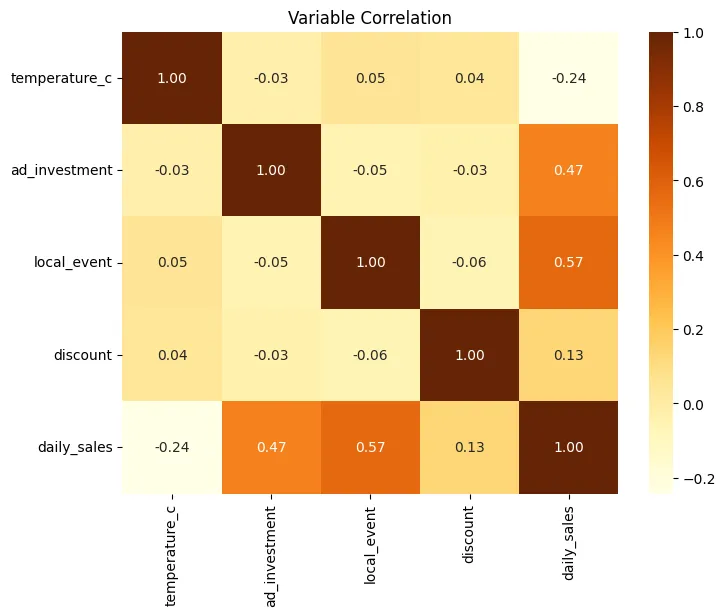 Heatmap de Correlación
Heatmap de Correlación
Vamos a descomponer la matriz de correlación, interpretando cada valor, pero antes recordemos qué significa cada número:
- 1.00: correlación positiva perfecta
- 0.00: no hay relación lineal
- -1.00: correlación negativa perfecta
La matriz es simétrica, es decir:
Corr(A, B) = Corr(B, A)
Por eso verás los mismos valores reflejados arriba y abajo de la diagonal.
La diagonal principal siempre es 1.00, porque cada variable está perfectamente correlacionada consigo misma.
Las variables incluidas son:
temperature_cad_investmentlocal_eventdiscountdaily_sales
temperature_c: Temperatura en grados Celsius.
- temperature_c - temperature_c = 1.00 Perfecta correlación consigo misma.
- temperature_c - ad_investment = -0.03 Relación prácticamente inexistente. La temperatura no influye en cuánto se invierte en publicidad.
- temperature_c - local_event = 0.05 Correlación muy débil positiva. Los eventos locales no dependen realmente del clima en este dataset.
- temperature_c - discount = 0.04 Sin relación relevante. Los descuentos no parecen aplicarse según temperatura.
- temperature_c - daily_sales = -0.24
Correlación negativa débil-moderada.
Cuando la temperatura aumenta, las ventas tienden a bajar ligeramente.
Esto puede indicar:- El negocio vende productos que se consumen más en clima fresco.
- En días muy calurosos hay menos afluencia.
No es una relación fuerte, pero sí consistente.
ad_investment: Inversión en publicidad.
- ad_investment - ad_investment = 1.00
- ad_investment - local_event = -0.05 Prácticamente independencia. La inversión publicitaria no depende directamente de si hay evento.
- ad_investment - discount = -0.03 Sin relación. Inversión y descuentos parecen decisiones separadas.
- ad_investment - daily_sales = 0.47
Correlación positiva moderada.
Esto significa:- A mayor inversión, mayores ventas.
- La relación es significativa, pero no perfecta.
- Hay otros factores influyendo.
Estadísticamente, es un predictor importante.
local_event: Evento local.
- local_event - local_event = 1.00
- local_event - discount = -0.06 Relación casi nula. No parece que los eventos impliquen necesariamente descuentos.
- local_event - daily_sales = 0.57
Es la correlación más alta con ventas.
Interpretación:- Cuando hay evento local, las ventas aumentan notablemente.
- Es el factor más influyente del dataset.
- Representa una variable clave para el modelo.
En términos prácticos: Los eventos generan tráfico o demanda adicional.
discount: Descuento.
- discount - discount = 1.00
- discount - daily_sales = 0.13
Correlación positiva débil.
Significa:- Los descuentos tienen un impacto pequeño.
- No parecen ser el motor principal de ventas.
Posibles explicaciones:- Descuentos bajos
- Mala estrategia
- O efecto condicionado a otras variables
daily_sales: Ventas diarias.
Ya interpretamos todas sus correlaciones con las demás variables:
| Variable | Correlación |
|---|---|
| temperature_c | -0.24 |
| ad_investment | 0.47 |
| local_event | 0.57 |
| discount | 0.13 |
Ordenadas por impacto lineal:
- local_event (0.57)
- ad_investment (0.47)
- temperature_c (-0.24)
- discount (0.13)
¿Qué nos dice esto a nivel de modelado?
Lo primero es que las variables más predictivas para estimar ventas son:
- local_event
- ad_investment
Ambas deberían incluirse en el modelo.
Luego tenemos la multicolinealidad
Observamos que:
- Ninguna variable independiente tiene correlación alta con otra.
- Todos los valores entre predictores están cerca de 0.
Esto es excelente porque significa que no hay redundancia fuerte y que cada variable aporta información distinta.
Si tuviesemos valores cercanos a 1 o -1 entre predictores (por ejemplo, ad_investment y local_event), tendríamos que considerar eliminar o combinar variables para evitar problemas de multicolinealidad.
Asi que con todo esto podemos concluir:
- El principal motor de ventas son los eventos locales.
- La inversión publicitaria tiene un impacto claro y consistente.
- La temperatura afecta ligeramente de forma negativa.
- Los descuentos tienen impacto bajo.
- No hay multicolinealidad problemática.
- El dataset es apto para un modelo de regresión múltiple.
Con esta información, un gerente de la cafetería podría tomar decisiones estratégicas como:
- Prioriza campañas durante eventos locales.
- Mantén inversión publicitaria constante.
- Reevaluar estrategia de descuentos.
- Considerar estrategias específicas para días calurosos.
Paso 4: De los Datos a la Predicción (Modelado)
Con el EDA completado, transformamos el clima a un formato binario y alimentamos a un modelo de Regresión Lineal Simple.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# One-Hot Encoding: Convierte "Soleado" o "Lluvioso" en columnas de 0s y 1s
df_encoded = pd.get_dummies(df, columns=["clima"])
X = df_encoded.drop("ventas_diarias", axis=1)
y = df_encoded["ventas_diarias"]
# Dividimos: 80% para que el modelo aprenda, 20% para examinarlo después
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
modelo_cafeteria = LinearRegression()
modelo_cafeteria.fit(X_train, y_train)
# Hacemos predicciones con el modelo entrenado
predicciones = modelo_cafeteria.predict(X_test)
Paso 5: Calificando al Modelo
Ahora evaluemos que tan "certero" es nuestro algoritmo comparando las ventas contra sus predicciones.
mae = mean_absolute_error(y_test, predicciones)
rmse = np.sqrt(mean_squared_error(y_test, predicciones))
r2 = r2_score(y_test, predicciones)
print(f"MAE: ${mae:.2f}")
print(f"RMSE: ${rmse:.2f}")
print(f"R^2: {r2:.2f}")
Dando como resultado:
MAE: $55.39
RMSE: $74.51
: 0.88
¿Qué significan estos números?
- MAE (Error Absoluto Medio): En promedio, nuestras predicciones se desvían de las ventas reales por aproximadamente
$55.39. Esto nos da una idea de la magnitud del error en términos monetarios. - RMSE (Error Cuadrático Medio): Al penalizar más los errores grandeses, el RMSE de
$74.51indica que, aunque la mayoría de las predicciones están cerca, hay algunos casos donde el modelo se equivoca más significativamente. - (Puntuación de Determinación): Un de 0.88 significa que el modelo explica el 88% de la variabilidad en las ventas diarias. Esto es un resultado bastante bueno, indicando que el modelo captura la mayoría de los patrones presentes en los datos.
Grafico de Predicciones vs Realidad
plt.figure(figsize=(8,5))
sns.scatterplot(x=y_test, y=predictions)
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'r--') # Perfect reference line
plt.title("Predictions vs Actual Sales")
plt.xlabel("Actual Sales ($)")
plt.ylabel("Model Predictions ($)")
plt.show()
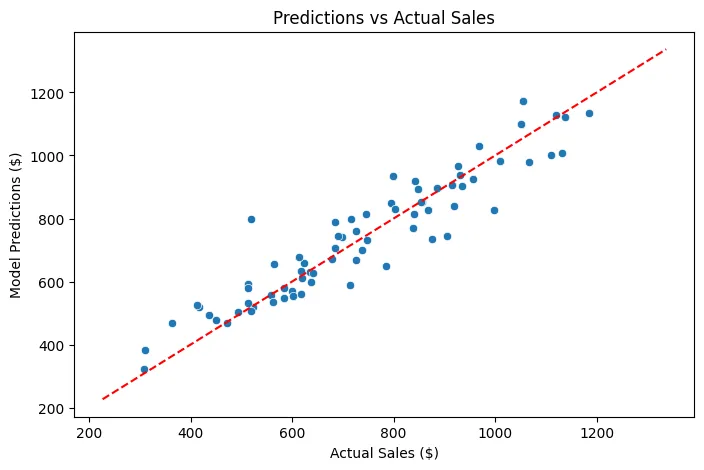 Gráfico de Predicciones vs Ventas Reales
Gráfico de Predicciones vs Ventas Reales
Como se observa, tenemos una línea de referencia (en rojo) que representa la perfección: si todas las ventas estuvieran exactamente en esa línea, el modelo sería perfecto, pero la realidad nunca será asi de ideal. Aún así, la mayoría de los puntos se agrupan alrededor de esa línea, lo que indica que el modelo tiene un buen desempeño general. Algunos puntos se alejan más, lo que refleja los casos donde el modelo no predice tan bien, posiblemente debido a factores no capturados en el dataset o a la variabilidad inherente en las ventas diarias.
Podemos también obtener los coeficientes del modelo para entender la importancia de cada variable:
coeficientes = pd.DataFrame({
'Variable': X.columns,
'Coeficiente': modelo_cafeteria.coef_
})
display(coeficientes.sort_values(by='Coeficiente', ascending=False))
Esto nos arroja el siguiente resultado:
| Feature | Coefficient |
|---|---|
| local_event | 261.839739 |
| weather_Rainy | 124.573377 |
| discount | 4.837618 |
| ad_investment | 2.482678 |
| temperature_c | -8.578684 |
| weather_Cloudy | -28.151991 |
| weather_Sunny | -96.421386 |
Lo que nos dice cada coeficiente es el impacto que tiene esa variable en las ventas diarias, manteniendo las demás constantes. Por ejemplo:
- Un evento local (local_event) aumenta las ventas en aproximadamente
$261.84. - Un día lluvioso (weather_Rainy) aumenta las ventas en aproximadamente
$124.57. - Un descuento (discount) aumenta las ventas en aproximadamente
$4.84por cada punto porcentual de descuento. - Cada dólar adicional invertido en publicidad (ad_investment) aumenta las ventas en aproximadamente
$2.48. - Cada grado Celsius adicional (temperature_c) disminuye las ventas en aproximadamente
$8.58 - Un día nublado (weather_Cloudy) disminuye las ventas en aproximadamente
$28.15. - Un día soleado (weather_Sunny) disminuye las ventas en aproximadamente
$96.42.
¿Qué mejoras podemos hacer al modelo?
- Feature Engineering: Explorar la creación de nuevas características a partir de las existentes. Por ejemplo, los términos de interacción entre
ad_investmentydiscount, otemperature_cyweather, podrían capturar relaciones más complejas. - Relaciones no lineales: El modelo actual es lineal. Si los diagramas de dispersión sugieren relaciones no lineales (p. ej., ventas que alcanzan su máximo a cierta temperatura y luego disminuyen), las características polinómicas u otros modelos no lineales (como Random Forest o Gradient Boosting) podrían capturarlas mejor.
- Aspectos de series temporales: Dado que los datos son de ventas diarias, podría haber patrones temporales (p. ej., efectos del día de la semana, estacionalidad no capturada completamente por
weather). Incorporar características como el día de la semana, el mes o utilizar modelos específicos para series temporales podría ser beneficioso. - Detección de valores atípicos: Investigar cualquier valor atípico potencial en los datos que pueda estar influyendo desproporcionadamente en los coeficientes y predicciones del modelo.
- Más datos: Si bien no siempre es factible, contar con puntos de datos más diversos (por ejemplo, de diferentes cafeterías, durante un período más prolongado y con condiciones más variadas) podría ayudar a que el modelo se generalice mejor.