
Paradigmas de aprendizaje automático y fundamentos matemáticos
Tipos de aprendizaje automático, algoritmos comunes y fundamentos matemáticos esenciales para entender cómo funcionan los modelos de machine learning.
Continuamos aprendiendo sobre Machine Learning, en esta ocasión nos adentraremos en los diferentes paradigmas de aprendizaje automático y los fundamentos matemáticos que sustentan estos modelos.
Artículo anterior: Fundamentos de Aprendizaje Automático
Paradigmas de Aprendizaje Automático
El machine learning NO comienza con algoritmos. EL proceso comienza con una comprension profunda del problema antes de seleccionar cualquier técnica o modelo, además de tres criterios fundamentales para determinar que enfoque y técnicas podemos usar:
- Naturaleza de los datos: Analizar el tipo de datos disponibles (etiquetados o no etiquetados) y su estructura.
- Tipo de salida esperada: ¿Qué tipo de resultado esperamos obtener? ¿Una categoría, un número continuo, o una estructura oculta?
- Interacción con el entorno: ¿El modelo necesita aprender a través de la interacción con un entorno dinámico?
Aprendizaje Supervisado
El aprendizaje supervisado requiere un conjunto de datos donde cada ejemplo de entrada X está asociado con una etiqueta o salida Y. El objetivo del modelo es aprender una función que mapee las entradas a las salidas correctas.
En función de esto, el conjunto de datos de entrenamiento se representa como un conjunto de pares , donde es la entrada y es la etiqueta correspondiente. El modelo de aprendizaje supervisado intenta encontrar una función f que pueda predecir la salida Y a partir de la entrada X:
Dependiendo del tipo de salida, el aprendizaje supervisado se puede dividir en:
- Clasificación: Cuando la salida Y es una categoría discreta (es decir, un valor categórico). Por ejemplo, clasificar si una imagen contiene un gato o un perro, si un número es par o impar, o si un correo electrónico es spam o no spam.
- Regresión: Cuando la salida Y es un valor continuo (es decir, un número real). Por ejemplo, hacer una predicción de las ventas futuras basándose en datos históricos, predecir el precio de una casa basándose en sus características, o estimar la temperatura de una ciudad en función de factores climáticos.
Una regla que nos puede servir para detectar si un problema es de clasificación o regresión es, si la respuesta es "¿Cuánto?" entonces es un problema de regresión, pero si la respuesta es "¿Cuál?" entonces es un problema de clasificación.
Objetivo: Aprender una función que mapee las entradas a las salidas correctas, minimizando el error entre las predicciones del modelo.
Aprendizaje No Supervisado
En el aprendizaje no supervisado, el modelo recibe solo las entradas X sin etiquetas asociadas: . Lo que se busca es encontrar patrones o estructuras subyacentes en los datos. Algunos ejemplos de técnicas de aprendizaje no supervisado incluyen:
- Clustering: Agrupar datos similares en clusters. Por ejemplo, segmentar clientes en grupos basados en sus comportamientos de compra.
- Reducción de Dimensionalidad: Reducir el número de variables en un conjunto de datos mientras se conserva la mayor cantidad de información posible. Por ejemplo, usar PCA (Análisis de Componentes Principales) para visualizar datos en 2D o 3D.
Objetivo: Encontrar patrones o estructuras subyacentes en los datos sin etiquetas, como agrupamientos o representaciones más compactas.
Aprendizaje por Refuerzo
El aprendizaje por refuerzo se basa en la idea de que un agente aprende a tomar decisiones mediante la interacción con un entorno. El agente recibe recompensas o castigos en función de las acciones que toma, y su objetivo es maximizar la recompensa acumulada a lo largo del tiempo. En este paradigma, el agente aprende una política de acción que le permite tomar decisiones óptimas en función del estado actual del entorno. Un ejemplo clásico de aprendizaje por refuerzo es el juego de ajedrez, donde el agente aprende a jugar mejor a medida que juega más partidas y recibe retroalimentación sobre sus movimientos.
- Agente: El sistema que toma decisiones.
- Entorno: El mundo con el que el agente interactúa.
- Recompensa: La retroalimentación que el agente recibe después de tomar una acción.
- Política: La estrategia que el agente sigue para tomar decisiones.
Sus aplicaciones incluyen juegos, robótica y sistemas de recomendación.
Objetivo: Aprender a tomar decisiones óptimas mediante la interacción con un entorno, maximizando la recompensa acumulada a lo largo del tiempo.
Fundamentos Matemáticos
Es importante entender que el aprendizaje automático se basa en conceptos de álgebra lineal, cálculo, probabilidad y estadística. Estos fundamentos son esenciales para comprender cómo funcionan los modelos y cómo se optimizan.
Regresión
Utilizado en el aprendizaje supervisado.
¿Qué es un problema de regresión? Es un tipo de problema donde el objetivo es predecir un valor continuo encontrando la mejor línea (o plano) que se ajuste a los datos. Ya hablamos de ejemplos de aplicación como el cálculo de precios, ventas, etc.
La forma mas simple de regresión es la regresión lineal, que se puede expresar matemáticamente como:
Donde:
- es la variable dependiente (lo que queremos predecir).
- son las variables independientes (las características).
- es la intersección (el valor de cuando todas las son 0).
- son los coeficientes que representan la influencia de cada característica en la variable dependiente.
- es el valor de error o ruido, que representa la variabilidad no explicada por el modelo, es decir, lo que afecta a pero no está incluido en las variables independientes.
El objetivo del modelo de regresión es encontrar los valores de los coeficientes que minimicen la diferencia entre las predicciones del modelo y los valores reales de . Esto se puede lograr utilizando técnicas como el método de mínimos cuadrados.
El intercepto se representa como el primer elemento del vector de coeficientes , y es el valor de cuando todas las variables independientes en son cero, es decir, representa el punto de la línea de regresión donde cruza el eje Y.
La pendiente se representa por los coeficientes restantes en el vector , y cada coeficiente indica la cantidad de cambio en la variable dependiente por cada unidad de cambio en la variable independiente correspondiente en , manteniendo constantes las demás variables independientes. Gráficamente podemos verlo de la siguiente manera:
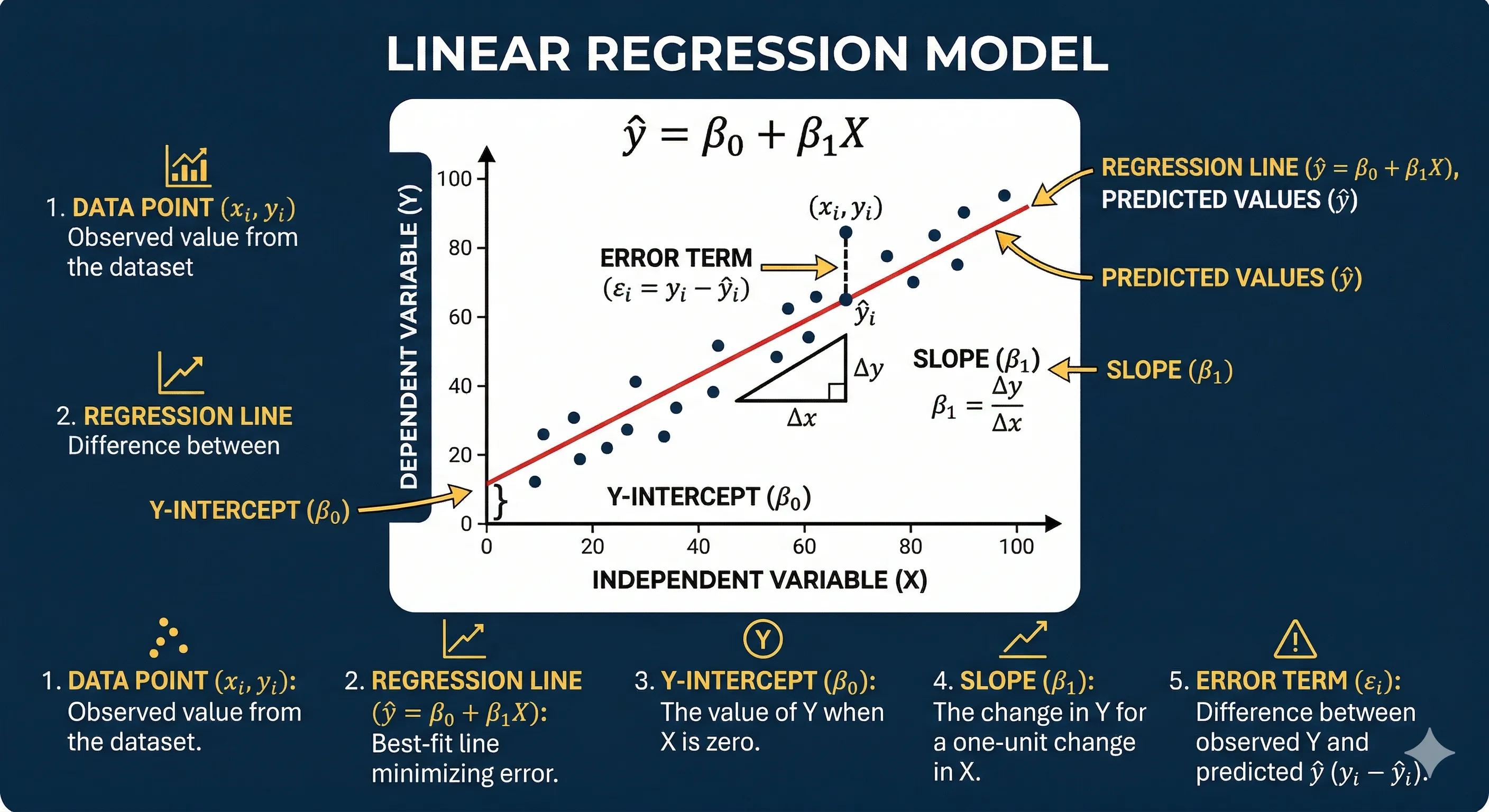 Gráfico de Regresión Lineal
Gráfico de Regresión Lineal
Cada punto negro representa un dato de entrenamiento, y la línea roja el modelo.
Lo importante aquí es entender que el objetivo principal es encontrar los valores de los coeficientes que hagan que las predicciones (la línea roja) sean lo más cercanas a los valores reales.
Es decir, no se busca predecir con exactitud, siempre (en la realidad) habrá un error o diferencia entre lo que el modelo predice y lo que realmente ocurre. EL término es la diferencia entre los valores predichos por el modelo y los valores reales:
Que también se puede expresar como:
Para medir el error podemos utilizar una función de pérdida. En el caso de la regresión lineal, una función de pérdida comúnmente utilizada es el error cuadrático medio (MSE, por sus siglas en inglés), que se define como:
Donde:
- es el número de ejemplos en el conjunto de datos.
- es el valor real de la variable dependiente para el ejemplo .
- es la predicción del modelo para el ejemplo .
Minimizar el MSE es equivalente a minimizar la suma de errores cuadrados:
O también:
A esto se le conoce como el método de mínimos cuadrados, y es una técnica comúnmente utilizada para encontrar los coeficientes que mejor se ajusten a los datos.
¿Por qué se usan cuadrados? Porque al elevar al cuadrado las diferencias, se penalizan más los errores grandes, lo que ayuda a encontrar una mejor línea de ajuste para los datos.
Veamos ahora como obtenemos esos coeficientes utilizando el método de mínimos cuadrados. Para encontrar los valores de y , podemos usar las siguientes fórmulas, que se obtienen al derivar la función de pérdida MSE con respecto a los coeficientes y establecer las derivadas iguales a cero:
Donde:
- es el número de ejemplos en el conjunto de datos.
- y son los valores de las variables independientes y dependientes para cada ejemplo.
- y son las medias (o promedios) de las variables independientes y dependientes, respectivamente.
Hagámos un ejemplo para entender como aplicarlo. Supongamos que tenemos un conjunto de datos con las siguientes características:
| Tamaño (m²) | Precio (USD) |
|---|---|
| 50 | 100,000 |
| 100 | 200,000 |
| 150 | 300,000 |
Queremos construir un modelo de regresión lineal para predecir el precio de una casa basándonos en su tamaño. En este caso, la variable independiente es el tamaño (X) y la variable dependiente es el precio (Y). El modelo de regresión lineal se puede expresar como:
Donde:
- es el precio de la casa.
- es el tamaño de la casa.
- es el intercepto.
- es la pendiente.
- es el error o ruido, que para este ejemplo asumiremos que es cero para simplificar.
Para encontrar los valores de y , podemos usar el método de mínimos cuadrados con la fórmula que mencionamos anteriormente:
Donde:
- es el número de ejemplos (en este caso, 3).
- y son los valores de tamaño y precio para cada ejemplo.
- y son las medias de las variables independientes y dependientes, respectivamente.
Tenemos entonces para este caso:
Resolviendo estas fórmulas, obtenemos los valores de y , que nos permiten construir el siguiente modelo:
Ahora podemos hacer predicciones para nuevos valores de tamaño. Por ejemplo, para una casa de 120 m², el modelo predice un precio de:
Los cálculos nos han dado los mejores coeficientes que minimizan el error cuadrático medio (pero no que lo eliminan completamente). Para medir el error de nuestro modelo, podemos calcular el MSE utilizando la fórmula que mencionamos antes:
Donde:
- es el número de ejemplos (en este caso, 3).
- son los valores reales de precio para cada ejemplo.
- son las predicciones del modelo para cada ejemplo, que se calculan usando el modelo de regresión lineal.
- Calculamos las predicciones para cada ejemplo:
- Para 50 m²:
- Para 100 m²:
- Para 150 m²:
- Calculamos los errores para cada ejemplo:
- Error para 50 m²:
- Error para 100 m²:
- Error para 150 m²:
- Elevamos al cuadrado y promediamos para obtener el MSE:
Para este caso un MSE de 0 nos indica que el modelo predice perfectamente los valores reales para este conjunto de datos de entrenamiento. Por supuesto que en la práctica los datos reales contendrán ruido y serán aún mayores, con mas variabilidad, por lo que el epsilon no será cero.
Para explorar más con la regresión puedes usar este Colab de Google que contiene un ejemplo completo de regresión lineal con Python: linear_regression
Clasificación
Utilizado en el aprendizaje supervisado.
Un problema de clasificacion busca predecir una variable de salida categórica a partir de un conjunto de variables independientes. Por ejemplo, predecir si un correo electrónico es spam o no spam basándose en su contenido, o saber si en la foto hay un gato o un perro.
Existen tres tipos principales de clasificación:
- Clasificación Binaria: Cuando hay dos clases posibles. Por ejemplo, clasificar si un paciente tiene una enfermedad (sí/no).
- Clasificación Multiclase: Cuando hay más de dos clases posibles. Por ejemplo, clasificar el tipo de flor (puede ser setosa, versicolor o virginica) basándose en sus características.
- Clasificación Multietiqueta: Cuando cada ejemplo puede pertenecer a múltiples clases, como clasificar las etiquetas de un artículo de noticias (política, economía, deportes) donde un artículo puede pertenecer a varias categorías.
La diferencia entre clasificación multiclase y multietiqueta es que en la primera cada ejemplo solo puede pertenecer a una clase, mientras que en la segunda un ejemplo puede pertenecer a múltiples clases simultáneamente.
Veámos un poco más sobre la clasificación binaria. En este caso, el objetivo es encontrar una función que mapee las entradas a una de las dos clases posibles.
La pregunta que el modelo de clasificación binaria intenta responder es: ¿Cuál es la probabilidad de que un ejemplo pertenezca a la clase 1 dado un conjunto de características? Esto se puede expresar matemáticamente como: Donde:
- es la probabilidad de que la clase sea 1 dado el vector de características x.
- es la función que mapea las características a la probabilidad.
El modelo más común para clasificación binaria es la regresión logística, que tiene el siguiente proceso:
- Calculamos una combinación lineal de las características:
- Aplicamos la función sigmoide para obtener una probabilidad:
- Probabilidad de clase:
Donde:
- es el intercepto.
- son los coeficientes que representan la influencia de cada característica en la variable dependiente.
- son las características o variables independientes.
- es la probabilidad de que la clase sea 1 dado el vector de características x.
Cada característica aporta evidencia a favor o en contra, imagina si la palabra "gratis" aparece en un correo electrónico, eso podría aumentar la probabilidad de que sea spam. Por otro lado, si la palabra "reunión" aparece, eso podría disminuir la probabilidad de que sea spam.
Esto nos proporciona no solo una clasificación, sino también una medida de confianza en esa clasificación a través de la probabilidad calculada por la función sigmoide.
La función sigmoide transforma cualquier valor real en un valor entre 0 y 1. La fórmula como se muestra arriba es:
Donde:
- es la combinación lineal de las características, es decir, .
- es el número de Euler, aproximadamente igual a 2.71828.
- es la salida de la función sigmoide, que representa la probabilidad de que la clase sea 1 dado el valor de z (rango entre 0 y 1).
Visualmente es algo así (con z en el eje X y en el eje Y):
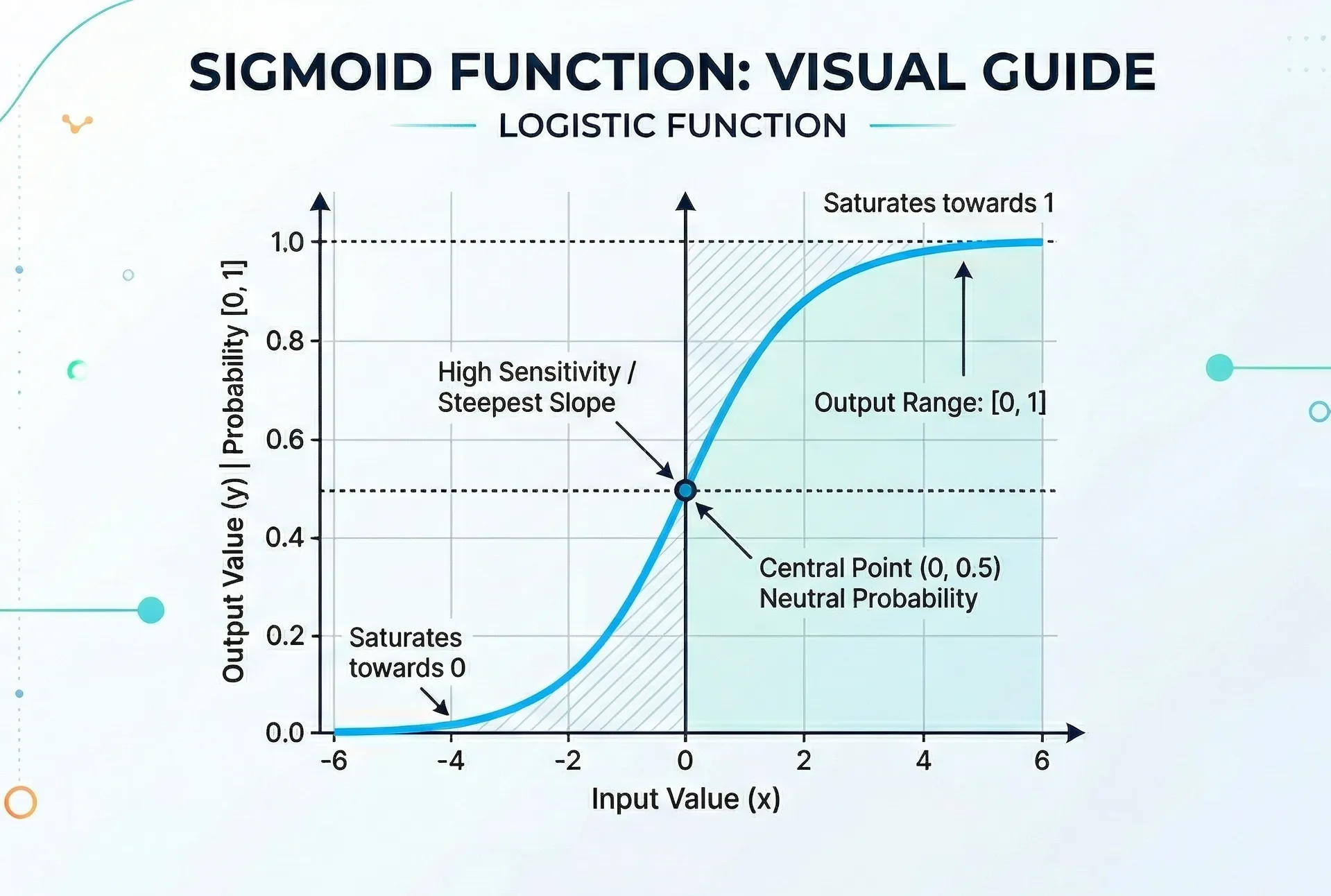 Gráfico de la Función Sigmoide
Gráfico de la Función Sigmoide
De aqui podemos sacar algunas conclusiones importantes:
- Cuando z es muy negativo, se acerca a 0, lo que indica una baja probabilidad de que la clase sea 1.
- Cuando z es muy positivo, se acerca a 1, lo que indica una alta probabilidad de que la clase sea 1.
- Cuando z es 0, es 0.5, lo que indica una probabilidad igual de que la clase sea 0 o 1.
EL valor de 0.5 comunmente se utiliza como umbral, de manera que:
- Si , se clasifica como clase 1.
- Si , se clasifica como clase 0.
Propiedades clave:
- Rango acotado entre 0 y 1
- Monotonía, si z aumenta, también aumenta)
- Asintótica, cuando y cuando
¿Cómo medimos el error en clasificación? Aquí se utilizan métricas como la entropía cruzada o log loss:
Pérdida para una muestra:
Pérdida promedio (o función de costo) para todo el conjunto de datos:
Donde:
- es el número de ejemplos en el conjunto de datos.
- es la etiqueta real (0 o 1) para el ejemplo .
- es la probabilidad predicha por el modelo para el ejemplo (valor entre 0 y 1).
¿Por qué se usa la entropía cruzada?
- Penaliza más las predicciones incorrectas con alta confianza.
- Es una función de pérdida convexa, lo que facilita la optimización mediante métodos como el descenso de gradiente.
- Interpretación probabilística, ya que se basa en la probabilidad predicha por el modelo.
El comportamiento de la función de pérdida se muestra en la siguiente gráfica:
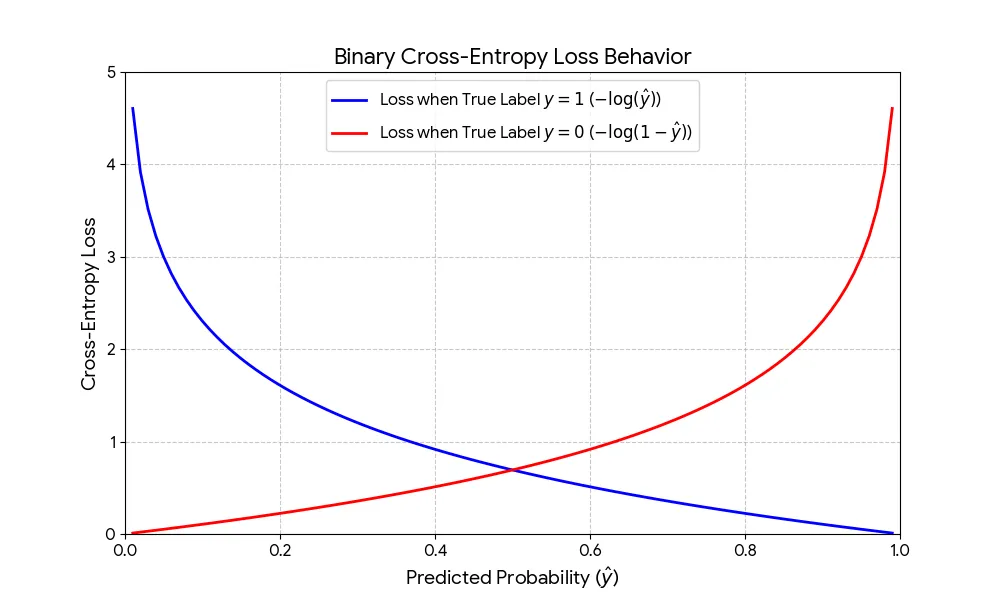 Gráfico de la Función de Pérdida de Entropía Cruzada
Gráfico de la Función de Pérdida de Entropía Cruzada
La función penaliza más las predicciones incorrectas con alta confianza, lo que se refleja en la forma de la curva.
- Cuando la etiqueta real es 1 (y=1) (línea azul):
- La fórmula se simplifica a
- Si se acerca a 1, la pérdida se acerca a 0 (buena predicción).
- Si se acerca a 0, la pérdida se dispara a infinito (mala predicción).
- Cuando la etiqueta real es 0 (y=0) (línea roja):
- La fórmula se simplifica a
- Si se acerca a 0, la pérdida se acerca a 0 (buena predicción).
- Si se acerca a 1, la pérdida se dispara a infinito (mala predicción).
La naturaleza logarítmica de la función es la que garantiza que el modelo sea penalizado severamente cuando se muestra "seguro pero equivocado", lo que obliga al modelo a ajustar sus pesos de forma más agresiva para mejorar las predicciones.
Validación y Optimización
Métricas de Evaluación
Para regresión, las métricas comunes incluyen:
- Error Cuadrático Medio (MSE): Promedio de los cuadrados de las diferencias entre los valores reales y las predicciones.
- Error Raíz Cuadrático Medio (RMSE): Raíz cuadrada del MSE, que tiene la misma unidad que la variable dependiente.
- Coeficiente de Determinación (R²): Proporción de la varianza en la variable dependiente que es explicada por el modelo.
- Error Absoluto Medio (MAE): Promedio de las diferencias absolutas entre los valores reales y las predicciones.
Para clasificación, las métricas comunes incluyen:
- Exactitud (Accuracy): Proporción de predicciones correctas sobre el total de ejemplos.
- Precisión (Precision): Proporción de verdaderos positivos sobre el total de predicciones positivas.
- Recall (Sensibilidad): Proporción de verdaderos positivos sobre el total de ejemplos reales positivos.
- F1 Score: Media armónica de la precisión y el recall, que proporciona una medida equilibrada entre ambos.
La elección de la métrica adecuada depende del contexto del problema y de las consecuencias de los errores de clasificación. Por ejemplo, en un problema de detección de fraude, es más importante minimizar los falsos negativos (no detectar un fraude) que los falsos positivos (marcar una transacción legítima como fraude), por lo que el recall podría ser una métrica más relevante que la precisión.
Optimización
La optimización de modelos de machine learning se refiere al proceso de ajustar los parámetros del modelo para minimizar la función de pérdida. Esto se puede lograr mediante técnicas como el descenso de gradiente, que iterativamente ajusta los pesos del modelo en la dirección que reduce la pérdida.
El descenso de gradiente se puede expresar matemáticamente como:
Donde:
- representa los parámetros del modelo (por ejemplo, los coeficientes en regresión).
- es la tasa de aprendizaje, que controla el tamaño de los pasos que se dan en cada iteración.
- es el gradiente de la función de pérdida con respecto a los parámetros, que indica la dirección de mayor aumento de la pérdida.
El proceso de optimización continúa hasta que se alcanza un criterio de convergencia, como un número máximo de iteraciones o una mejora mínima en la función de pérdida.
- Posee una tasa de aprendizaje () que controla el tamaño de los pasos que se dan en cada iteración (típicamente un valor pequeño como 0.01 o 0.001).
- El gradiente () es un vector que contiene las derivadas parciales de la función de pérdida con respecto a cada parámetro, indicando la dirección de mayor aumento de la pérdida.
- El proceso de optimización continúa hasta que se alcanza un criterio de convergencia, como un número máximo de iteraciones o una mejora mínima en la función de pérdida.
Gráficamente:
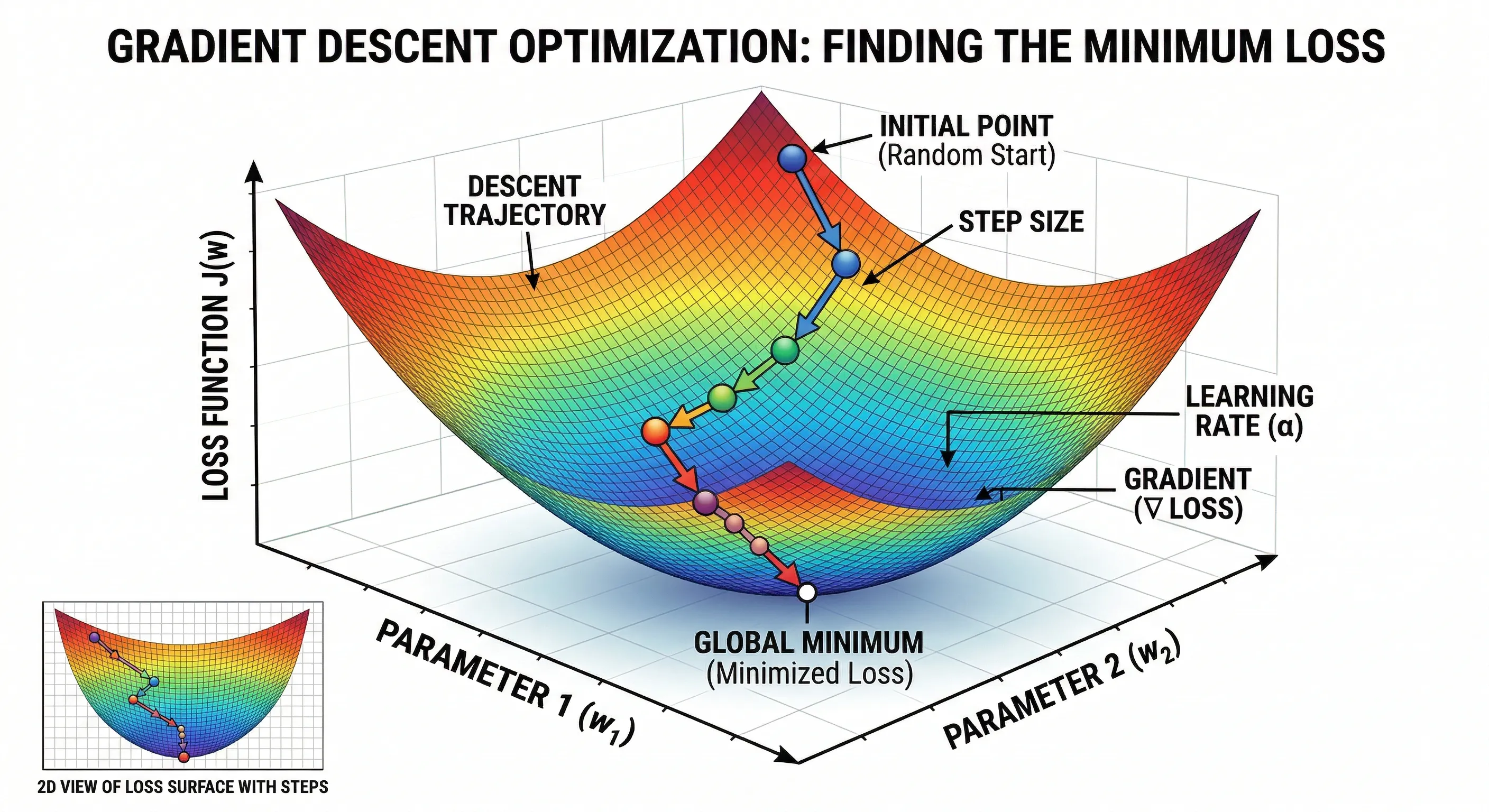 Optimización con Descenso de Gradiente
Optimización con Descenso de Gradiente
- Se inicia con un punto aleatorio en la función de pérdida (INITIAL POINT).
- Se calcula el gradiente en ese punto, que indica la dirección de mayor aumento de la pérdida.
- Se actualizan los parámetros del modelo en la dirección opuesta al gradiente, con un paso controlado por la tasa de aprendizaje (LEARNING RATE / STEP SIZE).
- Este proceso se repite iterativamente hasta que se alcanza un mínimo local o global de la función de pérdida, lo que indica que el modelo ha sido optimizado.
La tasa de aprendizaje es crucial para el éxito del proceso de optimización:
- DIVERGENCIA: Si la tasa de aprendizaje es demasiado alta, el modelo puede divergir, saltando por encima del mínimo y aumentando la pérdida.
- CONVERGENCIA LENTA: Si la tasa de aprendizaje es demasiado baja, el proceso de optimización puede ser muy lento, tardando mucho tiempo en converger o quedándose atrapado en un mínimo local.
- CONVERGENCIA ÓPTIMA: Una tasa de aprendizaje adecuada permite que el modelo converja de manera eficiente hacia un mínimo global o local, optimizando la función de pérdida de manera efectiva.
El Proceso de Machine Learning
Podemos resumir el proceso de ML en:
- Paradigma de aprendizaje: Elegir el tipo de aprendizaje (supervisado, no supervisado, por refuerzo) según el problema a resolver.
- Define el tipo de problema y datos disponibles.
- Modelo matemático: Seleccionar un modelo adecuado (regresión, clasificación, clustering) y entender su formulación matemática.
- Establece la relación matemática entre entrada y salida.
- Función de pérdida/costo: Definir una función de pérdida que mida el error del modelo y que se pueda optimizar.
- Cuántifica que tan malo es el modelo en sus predicciones.
- Optimización: Utilizar técnicas como el descenso de gradiente para ajustar los parámetros del modelo y minimizar la función de pérdida.
- Encuentra los mejores parámetros para que el modelo haga buenas predicciones.
- Evaluación: Medir el rendimiento del modelo utilizando métricas adecuadas para el tipo de problema (MSE para regresión, precisión/recall para clasificación, etc.).
- Valida el desempeño del modelo y su capacidad de generalización a datos no vistos.